Page: 1
/
17
Total 85 questions
Master CompTIA DataX Certification Exam DY0-001: Your Gateway to Data Excellence
Question 1
A statistician notices gaps in data associated with age-related illnesses and wants to further aggregate these observations. Which of the following is the best technique to achieve this goal?
Correct : C
Binning groups continuous age values into discrete intervals (e.g., age ranges), filling gaps by aggregating observations into broader categories. This directly addresses uneven or sparse age data by creating consistent age groups.
Start a Discussions
Submit Your Answer:
Question 2
The following graphic shows the results of an unsupervised, machine-learning clustering model:
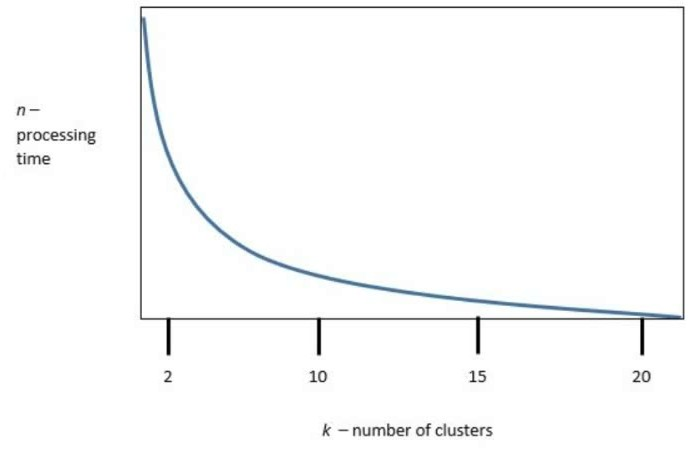
k is the number of clusters, and n is the processing time required to run the model. Which of the following is the best value of k to optimize both accuracy and processing requirements?
Correct : B
The curve shows a steep drop in processing time up to about k = 10, after which gains in speed taper off. Choosing 10 clusters balances sufficient model complexity with reasonable computational cost.
Start a Discussions
Submit Your Answer:
Question 3
A data scientist is developing a model to predict the outcome of a vote for a national mascot. The choice is between tigers and lions. The full data set represents feedback from individuals representing 17 professions and 12 different locations. The following rank aggregation represents 80% of the data set:
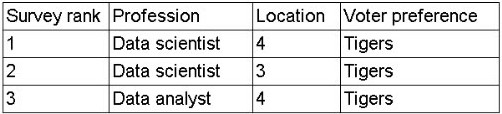
Which of the following is the most likely concern about the model's ability to predict the outcome of the vote?
Correct : D
The aggregated feedback covers only 80% of respondents, mostly from a few professions and locations, so the model hasn't ''seen'' the remaining 20% (and those underrepresented groups). Its performance on those unseen subsets (out-of-sample data) is therefore the primary concern for how well it will predict the actual vote.
Start a Discussions
Submit Your Answer:
Question 4
A data scientist has built an image recognition model that distinguishes cars from trucks. The data scientist now wants to measure the rate at which the model correctly identifies a car as a car versus when it misidentifies a truck as a car. Which of the following would best convey this information?
Correct : A
A confusion matrix directly shows true positives (cars correctly identified) and false positives (trucks misidentified as cars), giving you exactly the rates you're interested in.
Start a Discussions
Submit Your Answer:
Question 5
A data scientist uses a large data set to build multiple linear regression models to predict the likely market value of a real estate property. The selected new model has an RMSE of 995 on the holdout set and an adjusted R2 of .75. The benchmark model has an RMSE of 1,000 on the holdout set. Which of the following is the best business statement regarding the new model?
Correct : C
Although the new model's RMSE is technically lower (995 vs. 1,000), the fivepoint improvement on holdout data is negligible in most real-estate contexts and unlikely to produce meaningful business value over the existing benchmark.
Start a Discussions
Submit Your Answer:
Want to Unlock Everything for
CompTIA DY0-001 Exam?
CompTIA DY0-001 Exam?
By upgrading to Premium Access, you’ll instantly unlock:
Unlock 85 Premium Questions
- Exam Name: CompTIA DataAI Certification Exam
- Exam Code: DY0-001
- Last Update: 14-Jul-2026
- Formats: PDF, Web-based,
Desktop Practice - 24/7 Customer Support
 Price: $59 (PDF Format)
Price: $59 (PDF Format)